43种常见网络爬虫功能解析与访问量统计报告
本文系统整理了43种常见网络爬虫的详细功能解析,涵盖主流搜索引擎爬虫如Googlebot、Baiduspider,新兴AI爬虫如ChatGPT_User、ClaudeBot,以及各类SEO分析工具爬虫。每种爬虫均提供官方介绍和功能说明,并附有实际访问量统计数据,为网站管理员和技术人员提供全面的爬虫管理参考。内容基于真实网站监控数据,具有较高的实用价值和参考意义。
在网络上会有各种各样的爬虫,本人整理了经常访问本人网站的43种爬虫,提供了这些爬虫的简介和相关URL,并在最后提供了一段时间内,这些爬虫访问本人网站的数据供参考。
爬虫简介
| 360Spider | 360 搜索引擎的爬虫,用于索引网页内容以支持 360 搜索服务 | |
| AhrefsBot | Ahrefs 公司的 SEO 分析工具爬虫,用于收集网站数据以提供反向链接分析和 SEO 指标 | http://ahrefs.com/robot/ |
| Amazonbot | 亚马逊公司的搜索引擎爬虫,用于索引网页内容以支持 Alexa 搜索引擎和产品搜索 | https://developer.amazon.com/support/amazonbot |
| Applebot | 苹果公司的搜索引擎爬虫,用于为 Siri 和 Spotlight 搜索索引网页内容 | http://www.apple.com/go/applebot |
| Baiduspider | 百度搜索引擎的主要爬虫,用于抓取和索引网页内容以支持百度搜索 | http://www.baidu.com/search/spider.html |
| Baiduspider-render | 百度搜索引擎的渲染爬虫,用于执行 JavaScript 并获取动态渲染后的页面内容 | http://www.baidu.com/search/spider.html |
| Barkrowler | Babbar.tech 公司的爬虫,用于收集网站数据以提供 SEO 分析和反向链接研究 | https://babbar.tech/crawler |
| Bytespider | 字节跳动公司的搜索引擎爬虫,用于为今日头条等产品索引网页内容 | |
| CCBot | Common Crawl 项目的爬虫,用于大规模抓取网页并创建公开可用的网页存档数据集 | |
| ChatGPT_User | OpenAI 的 ChatGPT 用户代理,用于访问网页内容以支持 ChatGPT 的浏览功能 | https://openai.com/bot |
| ClaudeBot | Anthropic 公司的 Claude AI 助手爬虫,用于访问网页内容以支持 Claude 的实时信息获取 | |
| DataForSeoBot | DataForSeo 公司的 SEO 数据收集爬虫,用于收集网站数据以提供 SEO 分析服务 | https://dataforseo.com/dataforseo-bot |
| DingTalkBot | 阿里巴巴钉钉的链接预览爬虫,用于在聊天中生成链接预览卡片 | https://open-doc.dingtalk.com/microapp/faquestions/ftpfeu |
| DotBot | Moz 公司的 Open Site Explorer 爬虫,用于收集网站数据以提供 SEO 工具和分析 | https://opensiteexplorer.org/dotbot |
| DuckDuckBot | DuckDuckGo 搜索引擎的爬虫,用于索引网页内容以支持隐私保护的搜索服务 | http://duckduckgo.com/duckduckbot.html |
| Facebot | Facebook 和 Twitter 的链接预览爬虫,用于在社交平台上生成链接预览和卡片 | |
| GPTBot | OpenAI 的 GPT 模型训练数据收集爬虫,用于抓取网页内容以训练和改进 GPT 模型 | https://openai.com/gptbot |
| Gaisbot | 台湾中正大学的学术搜索引擎爬虫,用于索引学术网页内容 | http://gais.cs.ccu.edu.tw/robot.php |
| GenomeCrawlerd | 诺基亚公司的 Genome 项目爬虫,用于收集网络数据以支持网络研究和分析 | https://www.nokia.com/genomecrawler |
| GoRedirectChecker | 重定向检查工具爬虫,用于检测和分析网站的重定向链 | https://example.com/bot |
| Googlebot | Google 搜索引擎的主要爬虫,用于索引网页内容以支持 Google 搜索 | http://www.google.com/bot.html |
| Googlebot-Mobile | Google 搜索引擎的移动版爬虫,专门用于索引移动设备的网页内容 | http://www.google.com/bot.html |
| MJ12bot | Majestic SEO 公司的爬虫,用于收集网站数据以提供反向链接分析和 SEO 工具 | http://mj12bot.com/ |
| NetcraftSurveyAgent | Netcraft 公司的网站调查爬虫,用于收集网站技术栈和服务器信息 | |
| OAI-SearchBot | OpenAI 的搜索功能爬虫,用于索引网页内容以支持 AI 搜索功能 | https://openai.com/searchbot |
| OI-Crawler | OpenIntel 项目的网络爬虫,用于大规模网络数据收集和研究 | https://openintel.nl/webcrawl/ |
| Qwantbot | Qwant 搜索引擎的爬虫,用于索引网页内容以支持欧洲的隐私保护搜索服务 | https://help.qwant.com/bot/ |
| SEMrushBot | SEMrush 公司的 SEO 分析工具爬虫,用于收集网站数据以提供 SEO 和营销分析 | |
| SaluteBot | 未知来源的爬虫,可能是用于网站监控或数据收集的工具 | |
| SemrushBot | SEMrush 公司的标准 SEO 分析爬虫,用于收集网站数据以提供 SEO 工具和服务 | http://www.semrush.com/bot.html |
| SemrushBot-BA | SEMrush 公司的品牌分析爬虫,专门用于品牌相关的 SEO 数据收集 | http://www.semrush.com/bot.html |
| ShapBot | 未知来源的爬虫,可能是用于网站分析或数据收集的工具 | |
| TurnitinBot | Turnitin 学术诚信检测服务的爬虫,用于索引网页内容以检测学术抄袭 | https://turnitin.com/robot/crawlerinfo.html |
| YandexBot | Yandex 搜索引擎的主要爬虫,用于索引网页内容以支持俄罗斯最大的搜索引擎 | http://yandex.com/bots |
| YandexFavicons | Yandex 搜索引擎的图标收集爬虫,专门用于抓取网站的 favicon 图标 | http://yandex.com/bots |
| YandexUserproxy | Yandex 搜索引擎的用户代理爬虫,用于模拟用户访问以获取页面内容 | http://yandex.com/bots |
| YandexWebmaster | Yandex 搜索引擎的网站管理员工具爬虫,用于验证网站所有权和收集网站数据 | http://yandex.com/bots |
| YisouSpider | 神马搜索(UC 浏览器)的爬虫,用于索引网页内容以支持移动搜索服务 | |
| bingbot | 微软必应搜索引擎的爬虫,用于索引网页内容以支持 Bing 搜索服务 | http://www.bing.com/bingbot.htm |
| ev_crawler | Headline 公司的爬虫,用于收集网页内容以支持新闻和内容聚合服务 | https://headline.com/legal/crawler |
| meta-externalagent | Meta(Facebook)公司的外部代理爬虫,用于抓取链接预览和社交媒体卡片内容 | https://developers.facebook.com/docs/sharing/webmasters/crawler |
| msnbot | 微软 MSN 搜索引擎的爬虫,用于索引网页内容以支持 MSN 搜索服务 | http://search.msn.com/msnbot.htm |
| wpbot | 未知来源的爬虫,可能是用于网站监控、数据收集或 SEO 分析的工具 | https://forms.gle/ajBaxygz9jSR8p8G9 |
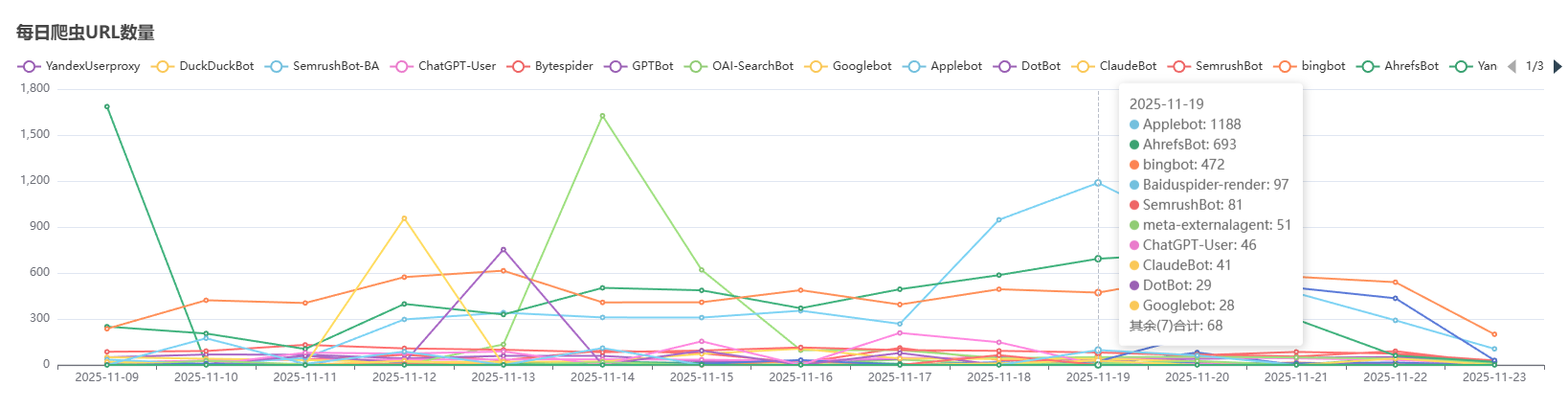
爬虫访问数据统计
网站爬虫种类很多,每种数量也很大,只要网站经常更新内容,爬虫几乎每天都会爬取网站。本人提供的2025年11月9日到2025年11月23日的爬虫数据供参考。
最后更新于6月前
本文由人工编写,AI优化,转载请注明原文地址: 43种常见爬虫简介及访问量统计
推荐阅读
评论 (3)
请 登录 后发表评论
这份爬虫统计太有用了,帮我认出了不少奇怪的访问来源。感谢作者整理分享,数据对网站分析很有参考价值!
这篇文章太实用了!作为站长,经常在日志里看到各种爬虫却不知道来源,这份详细的统计和功能介绍帮我解决了很多疑惑。感谢作者的无私分享!
太实用了!之前一直好奇哪些爬虫在访问我的网站,这份指南不仅列出了43种常见爬虫,还有访问量统计,对优化网站很有帮助。感谢作者整理分享!