PyTorch训练GPU占用率低?别被任务管理器骗了,用这招看真实利用率
在Windows上使用PyTorch训练模型时,任务管理器显示的GPU占用率较低是正常现象,因为PyTorch主要使用CUDA核心,而未调用3D、视频解码等功能。建议使用nvidia-smi dmon命令查看真实的GPU利用率,重点观察sm(流处理器利用率)和mem(显存带宽利用率)两项指标。若GPU占用率确实偏低,可通过在DataLoader中设置num_workers和pin_memory参数来提升。注意Windows下需将训练函数放在if __name__ == "__main__"中,且num_workers不宜过大,建议从2开始逐步增加,确保nvidia-smi中GPU利用率达到90%以上,同时调整batch_size使显存占用率也在90%左右。
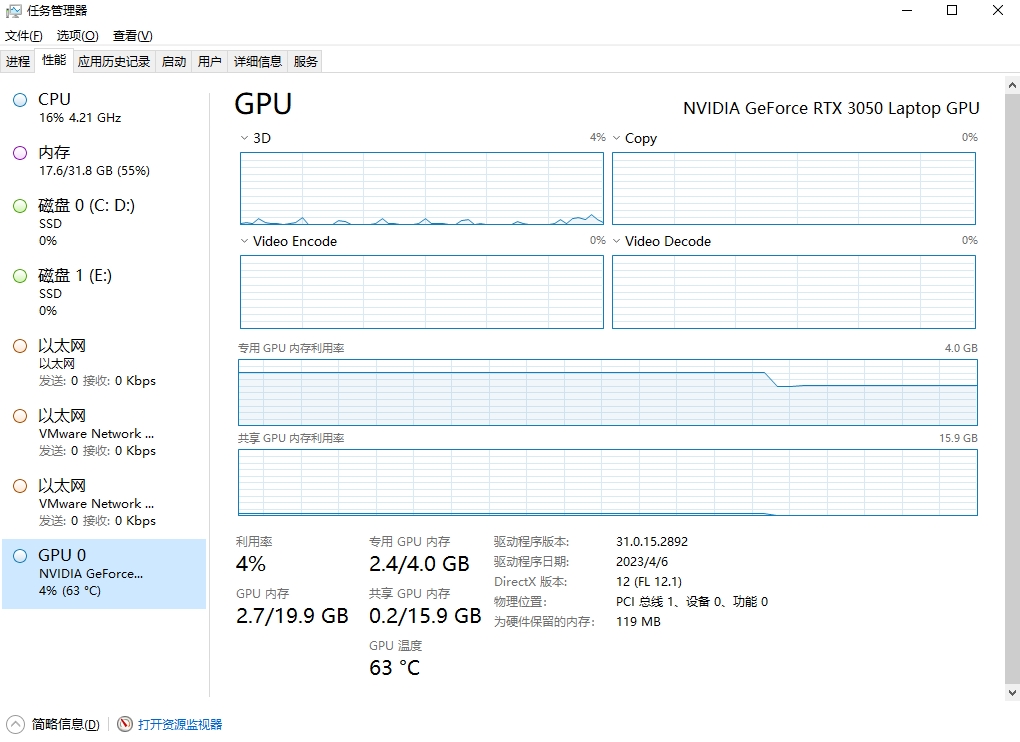
在Windows上使用PyTorch训练模型时,任务管理器里显示的GPU占用率比较低,这是正常的。因为PyTorch只利用了GPU中的CUDA核心,3D、视频解码等功能没有使用,平均下来,GPU的综合利用率比较低。可以使用nvidia-smi命令行工具查看真实的GPU占用率。
任务管理器里的GPU占用率
使用nvidia-smi查看真实的GPU占用率
命令(dmon表示以实时监控的形式查看):
nvidia-smi dmon
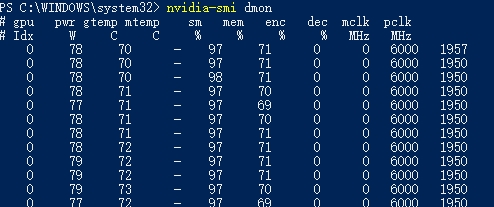
各列含义:
| 列名 | 全称 / 解释 | 单位/说明 |
|---|---|---|
| gpu | GPU 索引 (Idx) | 系统中的 GPU 编号(从 0 开始),多 GPU 时用于区分不同显卡。 |
| pwr | Power Draw | 当前 GPU 功耗(瓦特,W)。 |
| gtemp | GPU Temperature | GPU 核心温度(摄氏度,℃)。 |
| mtemp | Memory Temperature | 显存温度(℃),- 表示无传感器或未支持。 |
| sm | Streaming Multiprocessor | 流处理器利用率(百分比,%),反映 CUDA 核心的计算负载。 |
| mem | Memory Utilization | 显存带宽利用率(%),非显存容量占用,表示显存控制器的繁忙程度。 |
| enc | Encoder Utilization | 视频编码器(如 NVENC)利用率(%)。 |
| dec | Decoder Utilization | 视频解码器(如 NVDEC)利用率(%)。 |
| mclk | Memory Clock | 显存时钟频率(MHz),越高表示显存速度越快。 |
| pclk | Processor Clock | GPU 核心时钟频率(MHz),反映 GPU 核心的当前运行速度。 |
sm 和 mem 高百分比表明 GPU 计算或显存带宽成为瓶颈。在深度训练时,需要关注 sm 和 mem 是否接近 100%,确保 GPU 满载。
GPU占用率确实低的解决方案
可以在PyTorch DataLoader里设置num_workers和pin_memory参数解决。注意:在windows上设置num_workers后,训练函数必须放到if name == "main"里面,否则会报错。
注意:不要把num_workers设置的太大,创建worker也需要很多时间。可以从2开始加,只要保证使用nvidia-smi查看的GPU利用率在90%以上即可。然后调整batch_size,让显存占用率也在90%左右即可。
示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
from torchvision import datasets, transforms
num_epochs = 20
batch_size = 100
learning_rate = 0.001
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
train_dataset = datasets.MNIST(
root="./data", train=True, transform=transform, download=True
)
test_dataset = datasets.MNIST(
root="./data", train=False, transform=transform, download=True
)
train_loader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
test_loader = data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class CNNModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.dropout = nn.Dropout()
self.fc1 = nn.Linear(7 * 7 * 64, 1000)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.dropout(out)
out = self.fc1(out)
out = self.fc2(out)
return out
model = CNNModel().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
def train():
model.train()
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
output = model(images)
loss = criterion(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(
"Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}".format(
epoch + 1, num_epochs, i + 1, len(train_loader), loss.item()
)
)
def test():
model.eval()
with torch.no_grad():
total = 0
correct = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
output = model(images)
_, predict = torch.max(output, 1)
total += labels.size(0)
correct += (predict == labels).sum().item()
print("Accuracy of 10000 test images: {} %".format(correct / total * 100))
if __name__ == "__main__":
train()
test()
最后更新于1月前
本文由人工编写,AI优化,转载请注明原文地址: PyTorch训练GPU占用率低?别被任务管理器骗了,用这招看真实利用率
推荐阅读
VMware Workstation 16激活码及许可证密钥获取方法
33762024-09-29
ArcGIS Server 10.x出现498 Invalid token错误解决方法
1972026-06-10
超图iServer WMTS服务突破18级限制:自定义接口实现高精度瓦片加载
2482026-06-04
CodeBuddyIDE与Trae终极对决:谁是最强国产AI编程IDE?最新版本深度横评
34022025-09-25
XWiki只允许本机访问:Jetty绑定127.0.0.1配置方法
4702026-04-28
Windows系统PyTorch安装教程:CUDA 12.1环境配置与TorchText版本兼容性指南
34142024-06-21