PyTorch从零实现线性回归:手动梯度下降vs内置模块,小白也能轻松掌握
本文介绍了如何使用PyTorch从零实现线性回归,包括手动梯度下降和PyTorch内置模块两种方式。文章通过生成带噪声的数据集,训练模型学习y=wx+b中的参数w和b。手动实现部分详细演示了前向传播、计算均方误差损失、反向传播求梯度及参数更新过程;PyTorch模块部分则使用nn.Linear、MSELoss和SGD优化器简化代码。两种方法均经过1000次迭代成功拟合直线,参数接近w=1、b=0。文章强调掌握线性回归是深度学习的基础,PyTorch的自动微分机制能有效简化梯度计算。
在机器学习中,线性回归是最基础的入门问题之一。本文将介绍如何使用PyTorch从零开始实现线性回归,包括手动实现和使用PyTorch内置模块两种方式。
问题描述
我们有一个简单的线性关系:y = x + ε,其中ε是噪声。我们的目标是让模型学习到y = wx + b中的参数w和b,使得w接近1,b接近0。
数据生成
首先,我们生成100个数据点,x的范围是0到100,y在x的基础上加上随机噪声:
import torch
import matplotlib.pyplot as plt
x = torch.linspace(0, 100, 100).type(torch.float32)
y = x + torch.randn(100) * 10 # 添加标准差为10的高斯噪声
方法一:手动实现梯度下降
原理
线性回归的目标是最小化均方误差损失函数:
Loss = 1/n * Σ(wx + b - y)²
通过梯度下降法,不断更新参数w和b:
w = w - learning_rate * ∂Loss/∂w
b = b - learning_rate * ∂Loss/∂b
实现代码
learning_rate = 0.0001
# 随机初始化参数,设置requires_grad=True表示需要计算梯度
weight = torch.rand(1, requires_grad=True)
bias = torch.rand(1, requires_grad=True)
for i in range(1000):
# 前向传播:计算预测值
predictions = weight.expand_as(x) * x + bias.expand_as(x)
# 计算损失
loss = torch.mean((predictions - y) ** 2)
print('loss:', loss.item())
# 反向传播:计算梯度
loss.backward()
# 更新参数
weight.data.add_(-learning_rate * weight.grad.data)
bias.data.add_(-learning_rate * bias.grad.data)
# 清除梯度,防止累积
weight.grad.data.zero_()
bias.grad.data.zero_()
关键点说明
requires_grad=True:告诉PyTorch需要追踪这个张量的所有操作,以便后续计算梯度loss.backward():自动计算所有requires_grad=True的参数的梯度.data:访问张量的底层数据,避免构建计算图.zero_():梯度清零,因为PyTorch默认会累积梯度
方法二:使用PyTorch模块
PyTorch提供了更高级的API,让代码更加简洁和模块化。
定义模型
import torch.nn as nn
import torch.optim as optim
# 将数据reshape成模型需要的形状 [样本数, 特征数]
x_train = x.reshape(-1, 1)
y_train = y.reshape(-1, 1)
class Model(nn.Module):
def __init__(self):
super().__init__()
# nn.Linear是线性层:y = xA^T + b
self.fc = nn.Linear(1, 1)
def forward(self, x):
return self.fc(x)
model = Model()
训练模型
# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.0001)
for i in range(1000):
# 前向传播
predictions = model(x_train)
# 计算损失
loss = criterion(predictions, y_train)
print('loss:', loss.item())
# 反向传播
optimizer.zero_grad() # 清零梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 提取训练好的参数
weight = model.fc.weight[0, 0].item()
bias = model.fc.bias[0].item()
结果可视化
plt.figure(figsize=(10, 8))
xplot, = plt.plot(x, y, 'o') # 原始数据点
yplot, = plt.plot(x, weight * x + bias) # 拟合直线
plt.xlabel('X')
plt.ylabel('Y')
str1 = f'{weight:.4f}x + {bias:.4f}'
plt.legend([xplot, yplot], ['Data', str1])
plt.show()
运行效果
经过1000次迭代训练后,模型成功拟合出了线性关系:
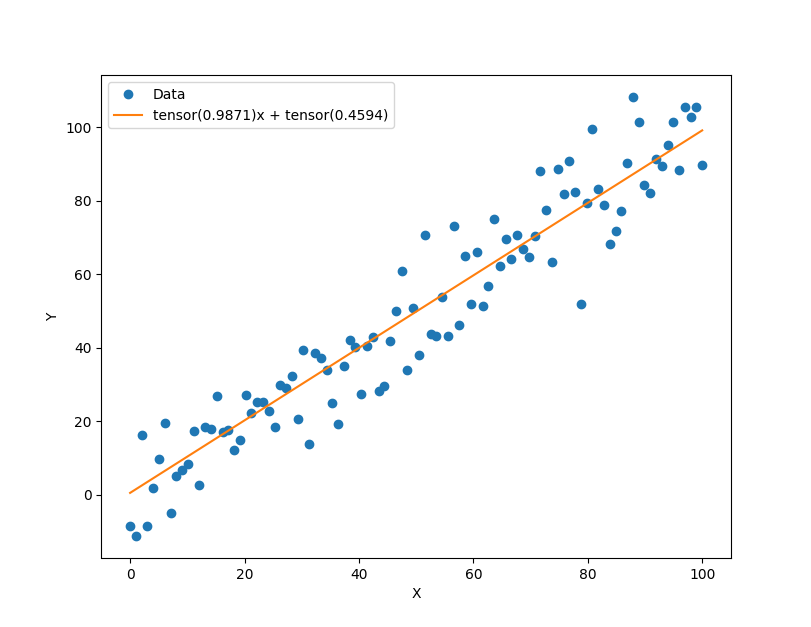
可以看到,拟合得到的直线很好地穿过了数据点的中心区域,参数接近预期的w=1、b=0。
总结
本文介绍了两种使用PyTorch拟合线性函数的方法:
- 手动实现:适合理解梯度下降的底层原理,可以看到每个步骤的细节
- 使用模块:适合实际项目开发,代码更简洁、更易维护
两种方法的核心思想都是:
- 定义模型(y = wx + b)
- 定义损失函数(MSE)
- 使用梯度下降更新参数
PyTorch的自动微分机制极大地简化了梯度计算的过程,让我们可以专注于模型设计本身。掌握了线性回归,就掌握了深度学习的基础,后续学习更复杂的神经网络会水到渠成。
最后更新于1月前
本文由人工编写,AI优化,转载请注明原文地址: PyTorch从零实现线性回归:手动梯度下降vs内置模块,小白也能轻松掌握
推荐阅读
CodeBuddyIDE与Trae终极对决:谁是最强国产AI编程IDE?最新版本深度横评
34422025-09-25
Windows系统PyTorch安装教程:CUDA 12.1环境配置与TorchText版本兼容性指南
34322024-06-21
VMware Workstation 16激活码及许可证密钥获取方法
33932024-09-29
XWiki只允许本机访问:Jetty绑定127.0.0.1配置方法
4872026-04-28
VMware Workstation 17许可证密钥及免费激活方法详解
52512024-09-29
为何说你的“自由意志”只是大脑的事后文案?从神经元到AI,意识本质揭秘
222026-07-09