从零上手四种GAN:用PyTorch实现全连接、DCGAN、CGAN和WGAN-GP生成逼真手写数字
在深度学习领域,生成对抗网络(Generative Adversarial Network, GAN)无疑是最引人瞩目的创新之一。它由Ian Goodfellow在2014年提出,通过让两个神经网络相互博弈的方式,实现了令人惊叹的数据生成效果。本文将带你从零开始,使用PyTorch实现四种不同风格的GAN,逐步生成逼真的MNIST手写数字。
本文将从最基础的全连接GAN开始,逐步深入到DCGAN、条件GAN和WGAN-GP,让你完整掌握GAN的发展脉络和实现细节。
简单生成对抗网络(CPU、全连接)
原理简介
最基础的GAN使用全连接层构建网络。生成器接收随机噪声,通过多层神经网络将其映射为图像;判别器则接收图像,输出该图像为真实的概率。两者在对抗中共同进化。
网络结构
- 生成器:1维噪声 → 200维隐藏层(Sigmoid) → 784维输出(Tanh)
- 判别器:784维输入 → 200维隐藏层(Tanh) → 1维输出(Sigmoid)
代码实现
import torch
import torch.nn as nn
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 真实数据
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
dataset = datasets.MNIST(r"./data", train=True, transform=transform, download=True)
# 生成随机数据
def generate_random(size):
random_data = torch.rand(size, 1)
return random_data
# 生成器
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(1, 200),
nn.Sigmoid(),
nn.Linear(200, 784),
# 由于数据集经过transforms.Normalize((0.5,),(0.5,))处理后范围是(-1,1),
# 所以生成器最后一层必须是nn.Tanh(),否则无法训练。
nn.Tanh(),
)
def forward(self, x):
return self.model(x)
# 判别器
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Tanh(),
nn.Linear(200, 1),
nn.Sigmoid(),
)
def forward(self, x):
return self.model(x)
generator = Generator()
discriminator = Discriminator()
# 优化器
optimizer_g = torch.optim.SGD(generator.parameters(), lr=0.001)
optimizer_d = torch.optim.SGD(discriminator.parameters(), lr=0.001)
# 损失函数
criterion = nn.MSELoss()
# 模型训练
counter = 0
loss_G = []
loss_D = []
for i, (image, _) in enumerate(dataset):
image = image.reshape(1, 784)
# 训练判别器
real_output = discriminator(image)
d_loss_real = criterion(real_output, torch.FloatTensor([[1.0]]))
optimizer_d.zero_grad()
d_loss_real.backward()
optimizer_d.step()
fake_data = generator(generate_random(1))
fake_output = discriminator(fake_data.detach())
d_loss_fake = criterion(fake_output, torch.FloatTensor([[0.0]]))
optimizer_d.zero_grad()
d_loss_fake.backward()
optimizer_d.step()
# 训练生成器
fake_data = generator(generate_random(1))
fake_output = discriminator(fake_data)
g_loss = criterion(fake_output, torch.FloatTensor([[1.0]]))
optimizer_g.zero_grad()
g_loss.backward()
optimizer_g.step()
# 记录损失
if i % 10 == 0:
counter += 1
loss_G.append(g_loss.item())
loss_D.append(d_loss_real.item())
if i % 100 == 0:
print(f"Epoch {i}, loss_G: {loss_G[-1]}, loss_D: {loss_D[-1]}")
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(loss_G, label="Generator Loss")
plt.plot(loss_D, label="Discriminator Loss")
plt.legend()
plt.show()
# 生成手写数字
rows, cols = 3, 3
figure = plt.figure(figsize=(8, 8))
# 在生成图像前将生成器设置为评估模式
generator.eval()
for row in range(rows):
for col in range(cols):
output = generator.forward(generate_random(1)).detach()
img = output.detach().numpy().reshape(28, 28)
index = row * cols + col
plot = figure.add_subplot(rows, cols, index + 1)
plot.imshow(img, interpolation="none", cmap="gray")
plot.axis("off")
plt.show()
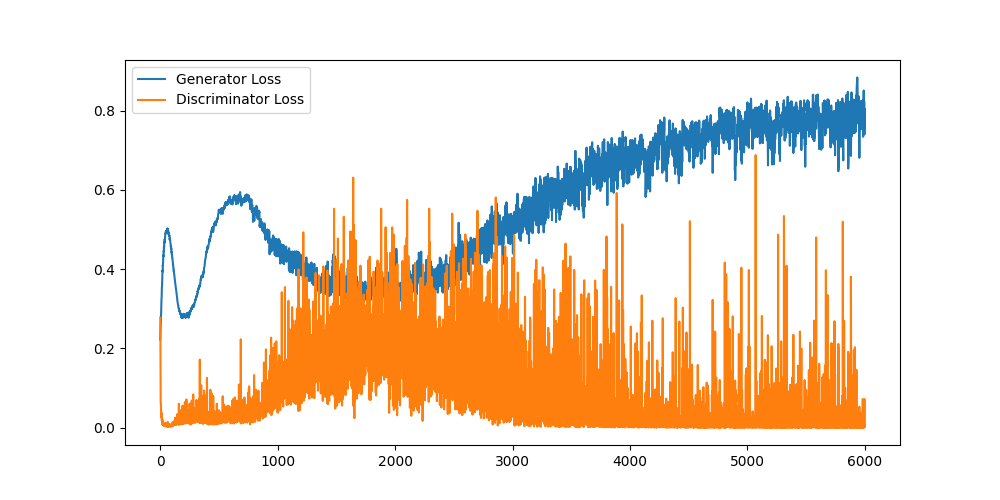
损失曲线
生成图片

结果分析
从损失曲线可以看出,生成器和判别器的损失在训练过程中不断波动,这是GAN训练的典型特征。生成的数字虽然能看出基本轮廓,但细节不够清晰,这是因为全连接层无法有效捕捉图像的空间结构信息。
卷积生成对抗网络(GPU、转置卷积)
原理简介
DCGAN(Deep Convolutional GAN)将全连接层替换为卷积层,能够更好地利用图像的空间结构。生成器使用转置卷积(又称反卷积)将低维噪声逐步上采样为图像;判别器使用常规卷积逐步下采样提取特征。
网络结构亮点
- 使用BatchNorm层稳定训练
- 生成器使用ReLU激活(输出层用Tanh)
- 判别器使用LeakyReLU激活
- 采用Adam优化器(lr=0.0002, betas=(0.5, 0.999))
代码实现
import torch
import torch.nn as nn
import torch.utils.data as data
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
num_epochs = 50
batch_size = 100
learning_rate = 0.0002
betas = (0.5, 0.999)
# 真实数据
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
dataset = datasets.MNIST(r"./data", train=True, transform=transform, download=True)
dataloader = data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 生成随机数据
def generate_random(batch_size, size):
random_data = torch.randn(batch_size, size)
return random_data.to(device)
# 生成器 - 使用转置卷积
class Generator(nn.Module):
def __init__(self):
super().__init__()
# 输入是长度为100的噪声向量
self.input_size = 100
# 起始特征图大小
self.ngf = 64
self.main = nn.Sequential(
# 输入是 Z: [batch, 100, 1, 1]
nn.ConvTranspose2d(self.input_size, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*8, 4, 4]
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*4, 8, 8]
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*2, 16, 16]
nn.ConvTranspose2d(self.ngf * 2, 1, 4, 2, 3, bias=False),
nn.Tanh(),
# 最终输出尺寸: [batch, 1, 28, 28]
)
def forward(self, x):
# 将输入重塑为 [batch, 100, 1, 1]
x = x.view(x.size(0), self.input_size, 1, 1)
return self.main(x)
# 判别器 - 使用卷积
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 特征图基础大小
self.ndf = 64
self.main = nn.Sequential(
# 输入是 [batch, 1, 28, 28]
nn.Conv2d(1, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf, 14, 14]
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*2, 7, 7]
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*4, 3, 3]
nn.Conv2d(self.ndf * 4, 1, 3, 1, 0, bias=False),
nn.Sigmoid(),
# 输出尺寸: [batch, 1, 1, 1]
)
def forward(self, x):
return self.main(x).view(-1, 1)
generator = Generator().to(device)
discriminator = Discriminator().to(device)
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1 or classname.find("BatchNorm") != -1:
if hasattr(m, "weight") and m.weight is not None:
nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
nn.init.constant_(m.bias.data, 0)
# 初始化生成器和判别器
generator.apply(weights_init)
discriminator.apply(weights_init)
# 优化器
optimizer_g = torch.optim.Adam(generator.parameters(), lr=learning_rate, betas=betas)
optimizer_d = torch.optim.Adam(
discriminator.parameters(), lr=learning_rate, betas=betas
)
# 损失函数
criterion = nn.BCELoss()
# 模型训练
generator.train()
discriminator.train()
loss_G = []
loss_D = []
for epoch in range(num_epochs):
for i, (images, _) in enumerate(dataloader):
# 图像数据已经是 [batch, 1, 28, 28] 格式,不需要reshape
images = images.to(device)
# 真实数据标签平滑(防止D过强)
real_labels = torch.full((batch_size, 1), 0.9, device=device)
fake_labels = torch.full((batch_size, 1), 0.1, device=device)
# 训练判别器
optimizer_d.zero_grad()
# 真实数据
real_output = discriminator(images)
d_loss_real = criterion(real_output, real_labels)
# 生成数据
z = generate_random(batch_size, 100)
fake_data = generator(z).detach() # 不要计算G的梯度
fake_output = discriminator(fake_data)
d_loss_fake = criterion(fake_output, fake_labels)
d_loss = (d_loss_real + d_loss_fake) / 2
d_loss.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
z = generate_random(batch_size, 100)
fake_data = generator(z)
fake_output = discriminator(fake_data)
g_loss = criterion(fake_output, real_labels)
g_loss.backward()
optimizer_g.step()
# 记录损失
if i % 20 == 0:
loss_G.append(g_loss.item())
loss_D.append(d_loss.item())
if i % 100 == 0:
print(
f"Epoch {epoch + 1}, Step {i + batch_size}, loss_G: {loss_G[-1]}, loss_D: {loss_D[-1]}"
)
# 训练结束后保存模型
torch.save(generator.state_dict(), "generator.pth")
torch.save(discriminator.state_dict(), "discriminator.pth")
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(loss_G, label="Generator Loss")
plt.plot(loss_D, label="Discriminator Loss")
plt.legend()
plt.show()
# 生成手写数字
rows, cols = 3, 3
figure = plt.figure(figsize=(8, 8))
# 在生成图像前将生成器设置为评估模式
generator.eval()
for row in range(rows):
for col in range(cols):
z = generate_random(1, 100)
output = generator(z)
img = output.detach().cpu().squeeze().numpy()
index = row * cols + col
plot = figure.add_subplot(rows, cols, index + 1)
plot.imshow(img, interpolation="none", cmap="gray")
plot.axis("off")
plt.show()
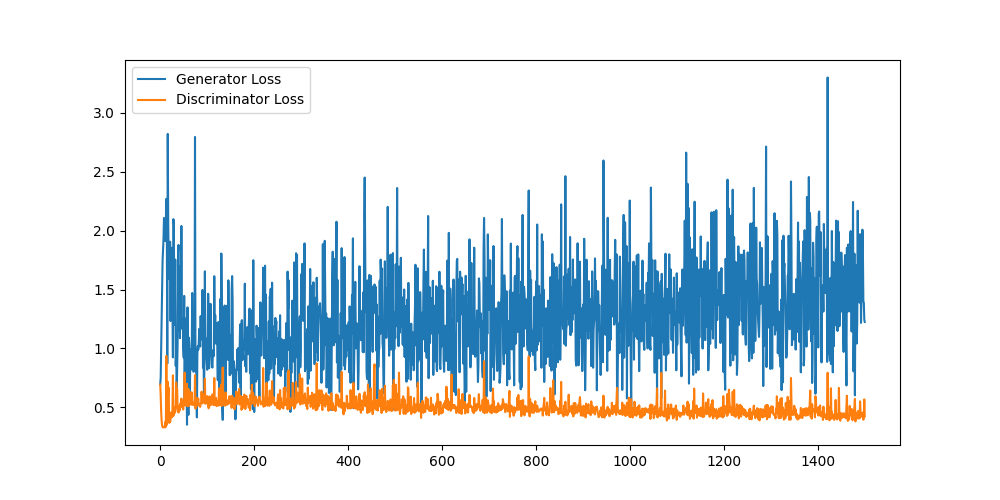
损失曲线
生成图片

结果分析
DCGAN生成的数字明显更加清晰、锐利,数字的轮廓和结构都很完整。这是卷积层带来的优势——它能有效学习图像的局部特征和空间关系。损失曲线虽然仍有波动,但整体趋势更加稳定。
条件生成对抗网络
原理简介
传统GAN无法控制生成的具体内容。条件GAN(CGAN)通过在生成器和判别器中都加入类别标签信息,实现了可控生成。你可以指定生成数字0-9中的任意一个。
关键改进
- 生成器:将噪声和one-hot标签拼接作为输入
- 判别器:在特征图后拼接标签信息
- 训练时:为生成器随机指定标签,判别器同时接收图像和标签
代码实现
import torch
import torch.nn as nn
import torch.utils.data as data
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
num_epochs = 50
batch_size = 100
learning_rate = 0.0002
betas = (0.5, 0.999)
n_classes = 10 # 数字0-9,共10个类别
# 真实数据
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
dataset = datasets.MNIST(r"./data", train=True, transform=transform, download=True)
dataloader = data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 生成随机数据
def generate_random(batch_size, size):
random_data = torch.randn(batch_size, size)
return random_data.to(device)
# 将标签转换为one-hot编码
def one_hot(labels, class_num):
batch_size = labels.size(0)
one_hot = torch.zeros(batch_size, class_num).to(device)
one_hot = one_hot.scatter_(1, labels.view(batch_size, 1), 1)
return one_hot
# 条件生成器 - 使用转置卷积
class Generator(nn.Module):
def __init__(self):
super().__init__()
# 输入是长度为100的噪声向量 + 10维的one-hot编码
self.noise_size = 100
self.label_size = n_classes
self.input_size = self.noise_size + self.label_size
# 起始特征图大小
self.ngf = 64
self.main = nn.Sequential(
# 输入是 Z+label: [batch, 110, 1, 1]
nn.ConvTranspose2d(self.input_size, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*8, 4, 4]
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*4, 8, 8]
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*2, 16, 16]
nn.ConvTranspose2d(self.ngf * 2, 1, 4, 2, 3, bias=False),
nn.Tanh(),
# 最终输出尺寸: [batch, 1, 28, 28]
)
def forward(self, noise, labels):
# 将标签转换为one-hot编码
labels_onehot = one_hot(labels, self.label_size)
# 将噪声和标签连接
x = torch.cat([noise, labels_onehot], 1)
# 将输入重塑为 [batch, input_size, 1, 1]
x = x.view(x.size(0), self.input_size, 1, 1)
return self.main(x)
# 条件判别器 - 使用卷积
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 特征图基础大小
self.ndf = 64
# 处理图像的卷积层
self.conv = nn.Sequential(
# 输入是 [batch, 1, 28, 28]
nn.Conv2d(1, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf, 14, 14]
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*2, 7, 7]
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*4, 3, 3]
)
# 最终判别层,结合图像特征和标签
self.final_layer = nn.Sequential(
nn.Conv2d(self.ndf * 4 + n_classes, self.ndf * 4, 3, 1, 0, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(self.ndf * 4, 1, 1, 1, 0, bias=False),
nn.Sigmoid(),
# 输出尺寸: [batch, 1, 1, 1]
)
def forward(self, x, labels):
# 处理图像
x = self.conv(x)
# 处理标签
batch_size = x.size(0)
labels_onehot = one_hot(labels, n_classes)
# 将标签扩展为与特征图相同的空间维度
labels_onehot = labels_onehot.view(batch_size, n_classes, 1, 1)
labels_onehot = labels_onehot.repeat(1, 1, x.size(2), x.size(3))
# 连接特征和标签
x = torch.cat([x, labels_onehot], 1)
# 最终判别
x = self.final_layer(x)
return x.view(-1, 1)
generator = Generator().to(device)
discriminator = Discriminator().to(device)
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1 or classname.find("BatchNorm") != -1:
if hasattr(m, "weight") and m.weight is not None:
nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
nn.init.constant_(m.bias.data, 0)
# 初始化生成器和判别器
generator.apply(weights_init)
discriminator.apply(weights_init)
# 优化器
optimizer_g = torch.optim.Adam(generator.parameters(), lr=learning_rate, betas=betas)
optimizer_d = torch.optim.Adam(
discriminator.parameters(), lr=learning_rate, betas=betas
)
# 损失函数
criterion = nn.BCELoss()
# 模型训练
generator.train()
discriminator.train()
loss_G = []
loss_D = []
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(dataloader):
# 图像数据已经是 [batch, 1, 28, 28] 格式,不需要reshape
images = images.to(device)
labels = labels.to(device)
# 真实数据标签平滑(防止D过强)
real_labels = torch.full((batch_size, 1), 0.9, device=device)
fake_labels = torch.full((batch_size, 1), 0.1, device=device)
# 训练判别器
optimizer_d.zero_grad()
# 真实数据
real_output = discriminator(images, labels)
d_loss_real = criterion(real_output, real_labels)
# 生成数据
z = generate_random(batch_size, 100)
# 为生成器创建随机标签
fake_digit_labels = torch.randint(0, n_classes, (batch_size,), device=device)
fake_data = generator(z, fake_digit_labels) # 不要计算G的梯度
fake_output = discriminator(fake_data.detach(), fake_digit_labels)
d_loss_fake = criterion(fake_output, fake_labels)
d_loss = (d_loss_real + d_loss_fake) / 2
d_loss.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
z = generate_random(batch_size, 100)
# 为生成器创建随机标签
fake_digit_labels = torch.randint(0, n_classes, (batch_size,), device=device)
fake_data = generator(z, fake_digit_labels)
fake_output = discriminator(fake_data, fake_digit_labels)
g_loss = criterion(fake_output, real_labels)
g_loss.backward()
optimizer_g.step()
# 记录损失
if i % 20 == 0:
loss_G.append(g_loss.item())
loss_D.append(d_loss.item())
if i % 100 == 0:
print(
f"Epoch {epoch + 1}, Step {i + batch_size}, loss_G: {loss_G[-1]}, loss_D: {loss_D[-1]}"
)
# 训练结束后保存模型
torch.save(generator.state_dict(), "generator_cgan.pth")
torch.save(discriminator.state_dict(), "discriminator_cgan.pth")
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(loss_G, label="Generator Loss")
plt.plot(loss_D, label="Discriminator Loss")
plt.legend()
plt.show()
# 生成指定数字的手写图像
generator.eval()
# 创建一个图表,显示每个数字的生成结果
plt.figure(figsize=(10, 10))
# 为每个数字生成3个样本
for sample in range(3):
for digit in range(10):
z = generate_random(1, 100)
# 创建指定数字的标签
label = torch.tensor([digit], device=device)
# 生成图像
output = generator(z, label)
img = output.detach().cpu().squeeze().numpy()
# 添加到图表
plt.subplot(3, 10, sample * 10 + digit + 1)
plt.imshow(img, cmap="gray")
plt.title(f"Number - {digit}")
plt.axis("off")
plt.tight_layout()
plt.show()
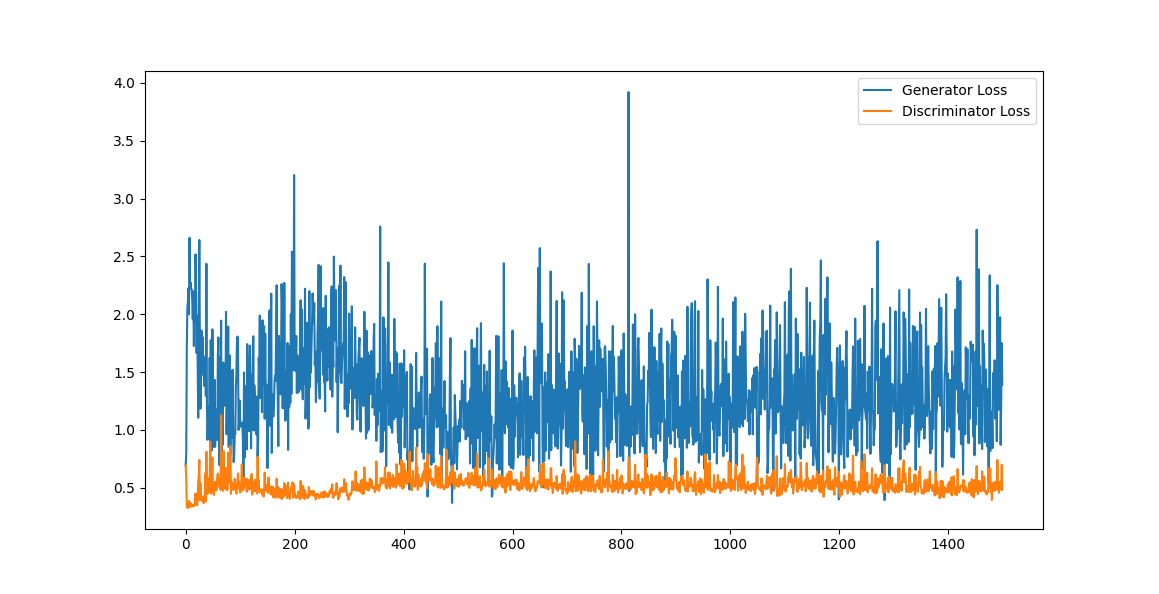
损失曲线
生成图片

结果分析
CGAN的生成结果非常惊艳——你可以清晰地看到每个数字的3个不同样本,而且生成质量与DCGAN相当。这证明了条件信息不仅能控制生成内容,还不会损害生成质量。损失曲线也表现出良好的收敛性。
WGAN-GP网络
原理简介
WGAN(Wasserstein GAN)通过使用Wasserstein距离替代JS散度,从根本上解决了传统GAN训练不稳定和模式崩溃的问题。WGAN-GP(Gradient Penalty)进一步用梯度惩罚替代权重裁剪,使训练更加平滑。
核心改进
- 移除Sigmoid:判别器输出未归一化的分数(critic)
- Wasserstein损失:最大化真实分数与生成分数之差
- 梯度惩罚:强制判别器的梯度范数接近1
- 训练比例:每训练5次判别器,训练1次生成器
代码实现
import torch
import torch.nn as nn
import torch.utils.data as data
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# WGAN-GP超参数
num_epochs = 50
batch_size = 100
learning_rate_g = 0.0001 # 生成器学习率
learning_rate_d = 0.0001 # 判别器学习率
betas = (0.0, 0.9) # WGAN推荐的Adam参数
n_critic = 5 # 判别器训练次数/生成器训练次数
lambda_gp = 10 # 梯度惩罚系数
# 真实数据
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
dataset = datasets.MNIST(r"./data", train=True, transform=transform, download=True)
dataloader = data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, drop_last=True
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 生成随机数据
def generate_random(batch_size, size):
random_data = torch.randn(batch_size, size)
return random_data.to(device)
# 生成器 - 使用转置卷积
class Generator(nn.Module):
def __init__(self):
super().__init__()
# 输入是长度为100的噪声向量
self.input_size = 100
# 起始特征图大小
self.ngf = 64
self.main = nn.Sequential(
# 输入是 Z: [batch, 100, 1, 1]
nn.ConvTranspose2d(self.input_size, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*8, 4, 4]
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*4, 8, 8]
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# 状态尺寸: [batch, ngf*2, 16, 16]
nn.ConvTranspose2d(self.ngf * 2, 1, 4, 2, 3, bias=False),
nn.Tanh(),
# 最终输出尺寸: [batch, 1, 28, 28]
)
def forward(self, x):
# 将输入重塑为 [batch, 100, 1, 1]
x = x.view(x.size(0), self.input_size, 1, 1)
return self.main(x)
# 判别器 - 使用卷积 (在WGAN中称为评论家/Critic)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
# 特征图基础大小
self.ndf = 64
self.main = nn.Sequential(
# 输入是 [batch, 1, 28, 28]
nn.Conv2d(1, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf, 14, 14]
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.LayerNorm([self.ndf * 2, 7, 7]), # 使用LayerNorm代替BatchNorm
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*2, 7, 7]
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.LayerNorm([self.ndf * 4, 3, 3]), # 使用LayerNorm代替BatchNorm
nn.LeakyReLU(0.2, inplace=True),
# 状态尺寸: [batch, ndf*4, 3, 3]
nn.Conv2d(self.ndf * 4, 1, 3, 1, 0, bias=False),
# 移除Sigmoid - WGAN不使用Sigmoid激活
# 输出尺寸: [batch, 1, 1, 1]
)
def forward(self, x):
return self.main(x).view(-1, 1)
generator = Generator().to(device)
discriminator = Discriminator().to(device)
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1 or classname.find("LayerNorm") != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
# 初始化生成器和判别器
generator.apply(weights_init)
discriminator.apply(weights_init)
# 优化器 - WGAN-GP推荐使用Adam,但β1=0
optimizer_g = torch.optim.Adam(generator.parameters(), lr=learning_rate_g, betas=betas)
optimizer_d = torch.optim.Adam(
discriminator.parameters(), lr=learning_rate_d, betas=betas
)
# 计算梯度惩罚
def compute_gradient_penalty(discriminator, real_samples, fake_samples):
# 随机权重项: 在真实和生成样本之间插值
alpha = torch.rand(real_samples.size(0), 1, 1, 1, device=device)
# 获取随机插值样本
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(
True
)
# 计算判别器对插值样本的输出
d_interpolates = discriminator(interpolates)
# 创建全1张量用于梯度计算
fake = torch.ones(real_samples.size(0), 1, requires_grad=False, device=device)
# 计算梯度
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
# 将梯度展平
gradients = gradients.view(gradients.size(0), -1)
# 计算梯度惩罚
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# 模型训练
generator.train()
discriminator.train()
loss_G = []
loss_D = []
for epoch in range(num_epochs):
for i, (images, _) in enumerate(dataloader):
# 图像数据已经是 [batch, 1, 28, 28] 格式,不需要reshape
images = images.to(device)
batch_size = images.size(0)
# ---------------------
# 训练判别器
# ---------------------
optimizer_d.zero_grad()
# 真实数据
real_output = discriminator(images)
real_loss = -torch.mean(real_output) # WGAN损失
# 生成数据
z = generate_random(batch_size, 100)
fake_data = generator(z)
fake_output = discriminator(fake_data.detach())
fake_loss = torch.mean(fake_output) # WGAN损失
# 梯度惩罚
gp = compute_gradient_penalty(discriminator, images, fake_data.detach())
# 总判别器损失
d_loss = fake_loss + real_loss + lambda_gp * gp
d_loss.backward()
optimizer_d.step()
# 每n_critic次判别器更新后,更新一次生成器
if i % n_critic == 0:
# ---------------------
# 训练生成器
# ---------------------
optimizer_g.zero_grad()
# 生成新数据
z = generate_random(batch_size, 100)
fake_data = generator(z)
fake_output = discriminator(fake_data)
# 生成器损失 - 最大化判别器对假样本的输出
g_loss = -torch.mean(fake_output)
g_loss.backward()
optimizer_g.step()
# 记录损失
loss_G.append(g_loss.item())
loss_D.append(d_loss.item())
if i % 100 == 0:
print(
f"Epoch {epoch + 1}, Step {i}, loss_G: {g_loss.item()}, loss_D: {d_loss.item()}, GP: {gp.item()}"
)
# 训练结束后保存模型
torch.save(generator.state_dict(), "wgan_gp_generator.pth")
torch.save(discriminator.state_dict(), "wgan_gp_discriminator.pth")
# 绘制损失曲线
plt.figure(figsize=(10, 5))
plt.plot(loss_G, label="Generator Loss")
plt.plot(loss_D, label="Discriminator Loss")
plt.legend()
plt.title("WGAN-GP Train Loss")
plt.savefig("wgan_gp_loss.png")
plt.show()
# 生成手写数字
rows, cols = 3, 3
figure = plt.figure(figsize=(8, 8))
# 在生成图像前将生成器设置为评估模式
generator.eval()
for row in range(rows):
for col in range(cols):
z = generate_random(1, 100)
output = generator(z)
img = output.detach().cpu().squeeze().numpy()
index = row * cols + col
plot = figure.add_subplot(rows, cols, index + 1)
plot.imshow(img, interpolation="none", cmap="gray")
plot.axis("off")
plt.title("WGAN-GP生成的手写数字")
plt.savefig("wgan_gp_samples.png")
plt.show()
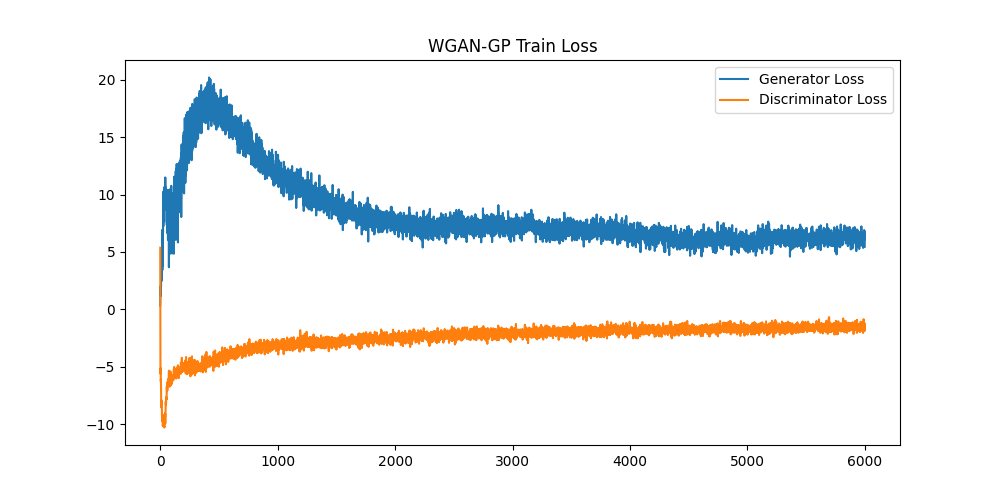
损失曲线
生成图片

结果分析
WGAN-GP的损失曲线最为平滑,这是Wasserstein距离的优势所在。生成的数字质量与DCGAN相当,但训练过程更加稳定可靠。尤其值得注意的是,损失值没有出现剧烈的震荡,说明模型收敛性很好。
总结
通过四种GAN的实现对比,我们可以得出以下结论:
技术演进路线
| 方法 | 核心创新 | 生成质量 | 训练稳定性 | 可控性 |
|---|---|---|---|---|
| 简单GAN | 对抗训练框架 | ⭐⭐ | ⭐⭐ | ❌ |
| DCGAN | 卷积架构 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ❌ |
| CGAN | 条件控制 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ✅ |
| WGAN-GP | Wasserstein距离 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ |
关键经验总结
- 数据预处理至关重要:将图像归一化到[-1,1]并与生成器的Tanh输出匹配
- 标签平滑能有效防止判别器过强:使用0.9/0.1代替1/0
- 卷积层比全连接层更适合图像生成:能保留空间结构信息
- WGAN-GP是最稳定的选择:适合生产环境部署
- 条件信息不会损害生成质量:CGAN实现了可控生成且质量不减
希望这篇博客能帮助你深入理解GAN的演进历程和实现细节。动手实践是最好的学习方式,快去训练你自己的生成模型吧!